本篇博客采用darknet训练自己的数据,那么在训练自己的数据之前,我们得先拥有自己数据,怎么得到呢?只能自己做了
安装labelImg
我用过精灵标注助手和labelImg两款标注工具,标注后得出得XML不一样。本篇博客采用labelImg工具标注图片。
环境:python3、ubuntu18.04
sudo apt-get install pyqt5-dev-toolssudo pip3 install lxml
下载labelImg源码
git clone https://github.com/tzutalin/labelImg.git
进入labelImg目录下
cd labelImg
再make qt5py3,建议不要make all。出现下面这种结果即为成功

然后python3 labelImg.py。出现界面即为成功。woc,这是我最顺利的一次。

制作自己的数据集
首先进入darknet目录下,再目录下新建文件夹VOC2019,并在VOC2019下新建Annotations,ImageSets,JPEGImages三个文件夹。在ImageSets新建Main文件夹。

将自己的数据集图片放到JPEGImages目录下,将标注文件放到Annotations目录下。接着开始标注数据。过程就随便说以下。[Open Dir]或Ctrl+u选择要标注的图片所在的根目录,[CreateRectBox]或w开始标注,鼠标框选目标区域后选择对应的标签类别,按空格或Ctrl+s保存,[Next Image]或d切换到下一张图片,标注错误的选框可选中后按[Delete]删除。要注意的是,如果不是使用原有的目标检测物体的类别,我们要打开data/predefined_classes.txt,修改默认类别为要检测的类别。
接着再VOC2019下新建test.py文件,将以下代码拷贝进去。在ImageSets的Maxin文件夹下将生成四个文件:train.txt,val.txt,test.txt,trainval.txt。
1 | import random |

YOLOV3的label标注的一行五个数分别代表类别(从 0 开始编号), BoundingBox 中心 X 坐标,中心 Y 坐标,宽,高。这些坐标都是 0~1 的相对坐标。和我们刚才标注的label不同,因此我们需要下面的py文件帮我们转换label。
wget https://pjreddie.com/media/files/voc_label.py
也可以在windows下好了拷到ubuntu下。总之把这个文件放到darknet文件夹下。打开voc_label.py文件,修改sets和classes。sets如下,classes根据自己的类别需要修改。

打开终端输入python voc_label.py,于是在当前目录生成三个txt文件2019_train.txt,2019_val.txt,2019_test.txt。在VOCdevkit文件夹下的VOC2019也会多生成一个文件夹labels。点开里面的文件就会发现以及转化成YOLOv3需要的格式了。数据集的制作完成,bingo!!!
局部修改
1、打开darknet下的cfg文件夹,修改voc.data。

根据自己的需要修改classes类别个数,train和valid的地址。names和backup不用修改。
2、修改data/voc.names和coco.names。打开对应的文件发现都是原本数据集里的类别,改成自己需求的类别就行。
3、修改参数文件cfg/yolov3-voc.cfg,用ctrl+f搜 yolo, 总共会搜出3个含有yolo的地方。每个地方都必须要改2处, filters:3*(5+len(classes))和classes类别数。

可修改:random,原本是1,显存小改为0。(是否要多尺度输出。)
报错&训练
首先下载darknet53的预训练模型:
wget https://pjreddie.com/media/files/darknet53.conv.74
开始训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
你以为就这样结束了吗?我就知道没怎么简单。又报错了,报错信息如下。

检查文件和路径,完全正确。
上网找了解决方案,如下
下载一个notepad++,打开文件。
选择 视图 -> 显示符号 -> 显示所有符号;
选择 编辑 -> 文档格式转换 -> 转换为UNIX(LF)格式;
转换完成后的格式如下:

注:
1.注意检查最后一行是否有LF标志。
2.为保证不出错,将所有训练过程中使用到的相关文件都修改。
我使用了上面的方法,发现我的文件格式本来就是对的。不需要改。那是什么问题呢?后来和一位同学一起瞎改cfg目录下voc.data文件,将train和valid的路径改成如下这样:
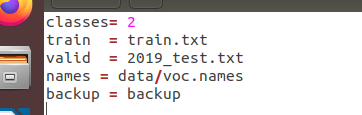
才开始运行。

