调试处理
关于训练深度最难的事情之一是要处理的参数的数量,从学习速率到Momentum(动量梯度下降法)的参数。如果使用Momentum或Adam优化算法的参数,β1,β2和ξ,也许你还得选择层数,也许还得选择不同层中隐藏单元的数量,也许还想使用学习率衰减。所以,使用的不是单一的学习率a。接着,当然可能还需要选择mini-batch的大小。
β1、β2、ξ推荐使用0.9、0.999、10-10。a是学习速率,学习速率是需要调试的最重要的超参数。
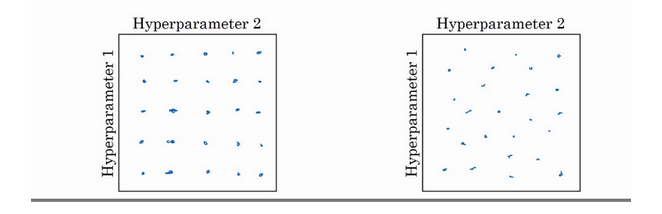
现在,如果我们尝试调整一些超参数,该如何选择调试值呢?在早一代的机器学习算法中,如果有两个超参数,这里会称之为超参1,超参2,常见的做法是在网格中取样点,像这样,然后系统的研究这些数值。这里放置的是5×5的网格,实践证明,网格可以是5×5,也可多可少,但对于这个例子,我们可以尝试这所有的25个点,然后选择哪个参数效果最好。当参数的数量相对较少时,这个方法很实用。
在深度学习领域,吴恩达老师推荐我们使用随机选择点方法,所以我们可以选择同等数量的点,对吗?25个点,接着,用这些随机取的点试验超参数的效果。之所以这么做是因为,对于要解决的问题而言,你很难提前知道哪个超参数最重要,正如之前看到的,一些超参数的确要比其它的更重要。
假如我们拥有三个超参数呢?这时我们搜索的就不只是一个方格了,而是一个立方体。超参数3代表第三维,接着,在三维立方体中取值,我们会实验更多的值。
实践中,需要搜索的可能不止三个超参数有时很难预知,哪个是最重要的超参数,对于具体应用而言,随机取值而不是网格取值表明,我们要探究了更多重要超参数的潜在值,无论结果是什么。
当我们给超参数取值时,另一个惯例是采用由粗糙到精细的策略。

比如在二维的那个例子中,你进行了取值,也许你会发现效果最好的某个点,也许这个点周围的其他一些点效果也很好,那在接下来要做的是放大这块小区域(小蓝色方框内),然后在其中更密集得取值或随机取值,聚集更多的资源,在这个蓝色的方格中搜索,如果你怀疑这些超参数在这个区域的最优结果,那在整个的方格中进行粗略搜索后,你会知道接下来应该聚焦到更小的方格中。在更小的方格中,你可以更密集得取点。所以这种从粗到细的搜索也经常使用。
为超参数选择合适的范围
讲个例子,假如我们在搜索超参数a,假设我们怀疑其值最小是0.0001,最大是1。假如我们把这个取值范围当作数轴,沿其随机均匀取值,那90%的值都会落在0.1到1之间。只有10%的搜索资源在0.0001到0.1之间。反而,用数标尺搜索超参数的方式会更合理,因此不使用线性轴。分别依次取0.0001,0.001,0.01,0.1,1,在对数轴上均匀随机取点,这样,在0.0001到0.001之间,就会有更多的搜索资源可用。
在python中,这可以通过numpy模块实现。
r=-4 x np.random.rand()
a=10r
对a随机取值,由上面第一行代码得出r的取值在[-4,0]之间,a的取值[10-4,100]之间。如果我们在10a和10b之间取值,在此例中,我们可以通过0.0001算出a的值为-4,b的值为0。我们要做的就是在[a,b]区间随机均匀的给r取值,然后设置a的值。所以总结一下,在对数坐标下取值,取最小值的对数就得到a的值,取最大值的对数就得到b值,所以现在你在对数轴上的10a到10b区间取值,在a,b间随意均匀的选取值,将超参数设置为10r,这就是在对数轴上取值的过程。
最后,还有一个例子是对β取值。用于计算指数的加权平均数。假设我们认为β是0.9到0.999之间的某个值,这也是我们想搜索的范围。
上面哪个例子说了如果想在0.9到0.999区间搜索,那就不能用线性轴取值。不要随机均匀在此区间取值,所以考虑这个问题最好的方法就是,我们要探究的是1-β,此值在0.1到0.001区间内,所以我们会给1-β取值,大概是从0.1到0.001。所以我们要做的是在[-3,-1]里随机均匀的给r取值。由1-β=10r推出β=1-10r,然后就变成了在特定的选择范围内超参数的随机取值。
超参数调试的方法
两种方法:
一种是你照看一个模型,通常是有庞大的数据组,但没有许多计算资源或足够的CPU和GPU的前提下,基本而言,只可以一次负担起试验一个模型或一小批模型,在这种情况下,即使当它在试验时,也可以逐渐改良。这是一个人照料一个模型的方法,观察它的表现,耐心的调试学习率。
另一种方法则是同时试验多种模型,你设置了一些超参数,尽管让它自己运行,或者是一天甚至多天,然后你会获得像这样的学习曲线,这可以是损失函数J或实验误差或损失或数据误差的损失,但都是你曲线轨迹的度量。同时你可以开始一个有着不同超参数设定的不同模型。
所以这两种方式的选择,是由你拥有的计算资源决定的,如果你拥有足够的计算机去平行试验许多模型,那绝对采用第二种方式,尝试许多不同的超参数,看效果怎么样。
归一化的激活函数
在深度学习兴起后,最重要的一个思想是它的一个算法——Batch归一化。batch归一化会使你的参数搜索问题变得很容易,使神经网络对超参数的选择更加稳定,超参数的范围会更加庞大,工作效果也很好,也会是你的训练更加容易。接下来看一下原理。
之前的逻辑回归,我们讲过归一化输入特征可以加快学习过程。计算了平均值,从训练集中减去平均值,计算了方差,接着根据方差归一化数据集。那么更深的模型呢?我们不仅输入了特征值x,而且第一层有激活值a[1],第二层有激活层a[2]等。那么如果我们想训练ω[3],b[3],那归一化a[2]岂不是更好?便于我们训练ω[3]和b[3]。
那么,我们能归一化每个隐藏层的a值吗?比如a[2],但不仅仅是a[2],可以是任何隐藏层的。a[2]的值是下一层的输入值,所以a[2]会影响ω[3],b[3]的训练。这就是batch归一化的作用。严格来说,归一化的是z[2],并不是a[2]。
在神经网络中,假设你有一些隐藏单元值从z[1]到z[m],这些来源于隐藏层,所以这样写会更准确,即z[ l ]( i )为隐藏层,i从1到m,所以已知这些值。如下,你要计算平均值,强调一下,所有这些都是针对 l 层,但已省略 l 及方括号,计算方法如下:

分母中加上ε以防止δ为0的情况。
所以现在我们已把这些z值标准化,化为含平均值 0 和标准单位方差,所以z的每一个分量都含有平均值 0 和方差 1,但我们不想让隐藏单元总是含有平均值 0 和方差 1,也许隐藏单元有了不同的分布会有意义,所以我们所要做的就是计算,我们称之为z~(i):

这里γ和β是模型的学习参数,所以我们使用梯度下降或一些其它类似梯度下降的算法,比如 Momentum 或者 Nesterov, Adam,接着更新γ和β,正如更新神经网络的权重一样。
γ和β的作用是可以随意设置z~(i) 的平均值,事实上,如果:

那么:

Batch 归一化的作用是它适用的归一化过程,不只是输入层,甚至同样适用于神经网络中的深度隐藏层。应用 Batch 归一化了一些隐藏单元值中的平均值和方差,不过训练输入和这些隐藏单元值的一个区别是,也许不想隐藏单元值必须是平均值 0 和方差 1。γ和β参数控制使得均值和方差可以是 0 和 1,也可以是其它值。
注意:均值不是平均值,是数学期望。
将Batch Norm拟合进神经网络

假设有一个这样的神经网络,之前的知识说过,我们可以认为每个单元负责计算两件事。第一,它先计算z,然后应用其到激活函数中再计算a,所以可以认为,每个圆圈代表着两步的计算过程。同样的,对于下一层而言,那就是$z^{[2]}_{1}$和$z^{[2]}_{2}$等。所以如果没有应用Batch归一化,会把输入X拟合到第一隐藏层,然后首先计算z[1],这是由ω[1]和b[1]两个参数控制的。接着,通常而言,会把z[1]拟合到激活函数以计算a[1]。但Batch归一化的做法是将z[1]值进行Batch归一化,简称BN,此过程将由β[1]和γ[1]两参数控制,这一操作会给你一个新的规范化的z[1]值(z~[1]),然后将其输入激活函数中得到a[1],即a[1]=g[1](z~[1])。

现在,你已在第一层进行了计算,此时Batch归一化发生在z的计算和a之间,接下来,你需要应用a[1]值来计算,此过程是由ω[1]和b[1]控制的。与第一层所做的类似,也会将进行Batch归一化,现在我们简称BN,这是由下一层的Batch归一化参数所管制的,即β[2]和γ[2],现在你得到z~[2],再通过激活函数计算出a[2]。
所以,得出结论的是batch归一化是发生在计算z和a之间的。与其使用没有归一化的z值,不如用归一化的z~值,也就是第一层的z~[1]。第二层同理,也是与其应用z值,不如应用z~[2]值。所以,我们以前的网络参数ω[1]、b[1]、ω[2]、b[2]将加上β[1]、β[2]、γ[1]、γ[2]等参数。注意:这里的β[1]、β[2]和超参数β没有关系
β1]、β[2]、γ[1]、γ[2]等是算法的新参数。接下来就是使用梯度下降法来执行它。举个例子,对于给定层,计算dβ[1],接着更新参数为β[1]=β[1]-αdβ[1]。你也可以使用Adam或RMSprop或Momentum,以更新参数β和γ,并不是只应用梯度下降法。
实践中,我们常将batch归一化和mibi-bacth一起使用。我们用第一个mini-batch{X[1]},然后应用ω[1]和b[1]计算z[1],接着用batch归一化得到z~[1],再应用激活函数得到a[1]。然后接着用ω[2]和b[2]计算z[2]。
类似的工作,你会在第二个mini-batch(X{2})上计算z[1],然后用Batch归一化来计算,所以Batch归一化的此步中,用的是第二个mini-batch(X{2})中的数据使归一化。然后在mini-batch(X{3})上同样这样做,继续训练。
先前说过每层的参数是ω[ l ]和b[ l ],还有β[ l ]和γ[ l ],请注意计算z的方式如下,z[ l ]=ω[ l ] * a[l-1]+b[ l ],但Batch归一化做的是,要看这个mini-batch,先将z[ l ]归一化,结果为均值0和标准方差,再由β和γ重缩放,但这意味着,无论b[ l ]的值是多少,都是要被减去的,因为在Batch归一化的过程中,要计算z[ l ]的均值,再减去平均值,在此例中的mini-batch中增加任何常数,数值都不会改变,因为加上的任何常数都将会被均值减去所抵消。
所以,我们在使用batch归一化时,我们可以消除b[ l ]这个参数。或者也可以设置为0。那么式子将从z[ l ]=ω[ l ] * a[l-1]+b[ l ]变为z[ l ]=ω[ l ] * a[l-1]。然后归一化z[ l ],得z~[ l ]=γ[ l ] * z[ l ]+β[ l ],所以最后我们会用β[ l ],以便决定z~[ l ]的取值。
总结一下关于如何用 Batch 归一化来应用梯度下降法:
假设使用 mini-batch梯度下降法,运行t = 1到 batch 数量的 for 循环,会在 mini-batchX{t}上应用正向 prop,每个隐藏层都应用正向 prop,用 Batch 归一化代替z[l]为z~[l]。接下来,它确保在这个 mini-batch 中,z值有归一化的均值和方差,归一化均值和方差后是z~[ l ] ,然后,你用反向 prop 计算:dw[ l ],db[l],dβ[ l ] ,dγ[ l ]。 尽管严格来说,因为要去掉b,这部分其实已经去掉了。最后,更新这些参数:
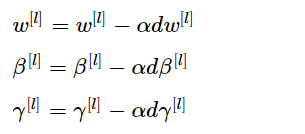
batch norm为什么会管用?
一个原因是,你已经看到如何归一化输入特征值x,使其均值为0,方差1,它又是怎样加速学习的,有一些从0到1而不是从1到1000的特征值,通过归一化所有的输入特征值x,以获得类似范围的值,可以加速学习。所以Batch归一化起的作用的原因,直观的一点就是,它在做类似的工作,但不仅仅对于这里的输入值,还有隐藏单元的值,这只是Batch归一化作用的冰山一角,还有些深层的原理,它会有助于你对Batch归一化的作用有更深的理解,让我们一起来看看吧。
Batch归一化有效的第二个原因是,它可以使权重比你的网络更滞后或更深层,比如,第10层的权重相比于神经网络中前层的权重更能经受得住变化。

看上面的素材。假设我们已经在某个网络上训练了所有黑猫的图像,如果我们将这个网络应用于有色猫。这种情况下,我们的效果可能不是很好。因为正面的例子不止左边的黑猫,还有右边其它颜色的猫。
所以我们要使数据改变分布,想法名字叫“Covariate shift”。想法是这样的,如果你已经学习了x到y的映射,如果x的分布改变了,那么你可能需要重新训练你的学习算法。这种做法同样适用于,如果真实函数由x到y映射保持不变,正如此例中,因为真实函数是此图片是否是一只猫,训练你的函数的需要变得更加迫切,如果真实函数也改变,情况就更糟了。
看上图,看第三层网络。此网络已经学习了参数ω[3]和b[3]。它还得到了一些值,称为$a^{[2]}_{1}$、$a^{[2]}_{2}$、$a^{[2]}_{3}$、$a^{[2]}_{4}$,但这些值也可以变为x1、x2、x3、x4。第三层隐藏层要做的是,找到一种方式使这些值映射到y帽。再看网络左边前三层(包括输入层),这个网络还有参数ω[2]、b[2]、ω[1]、b[1],如果这些参数改变,这些a[2]的值也会变。所以从第三层隐藏层的角度来看,这些隐藏单元的值在不断地改变,所以它就有了“Covariate shift”的问题。
Batch归一化做的,是它减少了这些隐藏值分布变化的数量。batch归一化讲的是当神经网络层更新参数时,batch归一化可以确保无论$z^{[2]}_{1}$、$z^{[2]}_{2}$、$z^{[2]}_{3}$、$z^{[2]}_{4}$怎么变化它们的均值和方差都保持不变。均值和方差是由β[2]和γ[2]决定的值,如果神经网络选择的话,可强制均值为0,方差为1,或其它任何均值和方差。
Batch归一化减少了输入值改变的问题,它的确使这些值变得更稳定,神经网络的之后层就会有更坚实的基础。即使使输入分布改变了一些,它会改变得更少。它做的是当前层保持学习,当改变时,迫使后层适应的程度减小了,我们可以这样想,它减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习,稍稍独立于其它层,这有助于加速整个网络的学习。
batch归一化还有一个作用,它有轻微的正则化效果。在mini-batch计算中,由均值和方差缩放的,因为是在mini-batch上计算的均值和方差,而不是在整个数据集上,它只是由一小部分数据估计得出的。所以和dropout相似,它往每个隐藏层的激活值上增加了噪音,dropout有增加噪音的方式,它使一个隐藏的单元,以一定的概率乘以0,以一定的概率乘以1,所以你的dropout含几重噪音,因为它乘以0或1。对比而言,Batch归一化含几重噪音,因为标准偏差的缩放和减去均值带来的额外噪音。这里的均值和标准差的估计值也是有噪音的,所以类似于dropout,Batch归一化有轻微的正则化效果,因为给隐藏单元添加了噪音,这迫使后部单元不过分依赖任何一个隐藏单元,类似于dropout。batch归一化给隐藏层增加了噪音,因此有轻微的正则化效果。因为添加的噪音很微小,所以并不是巨大的正则化效果。如果想得到dropout更大的正则化效果,可以将Batch归一化和dropout一起使用。
测试时的batch norm
batch归一化将数据以mini-batch的形式逐一处理,但在测试时,需要对每个样本逐一处理。

在训练时,这些就是用来执行Batch归一化的等式。在一个mini-batch中,你将mini-batch的z(i)值求和,计算均值,所以这里你只把一个mini-batch中的样本都加起来,我用m来表示这个mini-batch中的样本数量,而不是整个训练集。然后计算方差,再算$z^{(i)}_{norm}$,即用均值和标准差来调整,加上ξ是为了数值稳定性。z~(i)是用γ和β再次调整$z^{(i)}_{norm}$得到的。
请注意用于调节计算的μ和σ2是在整个mini-batch上进行计算,但是在测试时,不能将一个mini-batch中的6428或2056个样本同时处理,因此需要用其它方式来得到μ和σ2,而且如果只有一个样本,一个样本的均值和方差没有意义。那么实际上,为了将神经网络运用于测试,就需要单独估算μ和σ2,在典型的Batch归一化运用中,需要用一个指数加权平均来估算,这个平均数涵盖了所有mini-batch,接下来是具体解释。
选择 l 层,假设我们用mini-batch,X[1],X[2],X[3]……以及对应的y值等等,那么在 l 层训练X{1}时,就得到了μ{1}[ l ]。当我们训练第二个mini-batch,我们就得到了μ{2}[ l ],第三个mini-batch,就得到了μ{3}[1]值。正如我们之前用的指数加权平均来计算θ1,θ2,θ3的均值,当时是试着计算当前气温的指数加权平均,你会这样来追踪你看到的这个均值向量的最新平均值,于是这个指数加权平均就成了你对这一隐藏层的z均值的估值。同样的,你可以用指数加权平均来追踪你在这一层的第一个mini-batch中所见的的σ2值,以及第二个mini-batch中所见的的σ2值等等。因此在用不同的mini-batch训练神经网络的同时,能够得到你所查看的每一层的μ和σ2的平均数的实时数值。最后在测试时,我们只需要z值来计算$z^{(i)}_{norm}$,用μ和σ2的指数加权平均,用手头的最新数值来做调整,然后就可以用刚算出来的znorm和在神经网络训练过程中得到的β和γ参数来计算那个测试样本的z~值。
Softmax回归
前面的讲过逻辑回归属于二分类,如果我们有多种可能的类型呢?

假设我们不止需要识别猫,而是想识别猫、狗和小鸡。把猫当作类1,把狗当作类2,把小鸡当作类3。如果不属于以上任何一类,就分到“其它”或“以上均不符合”这一类,我把它叫做类0。所以上面图中第一张图为3类,第二张图为1类,第三张图为2类,第四张图为0类,依次类推。我们使用C来表示输入会被分入的类别总个数。在这个例子中,我们有四种可能的类别。当有四个分类时,指示类别的数字0-C-1。就是0、1、2、3。

最后一层的隐藏单元为4,为所分的类的数目。输出的值表示属于每个类的概率。它们加起来等于一。
Softmax的具体步骤如下:
在神经网络的最后一层,我们将会想往常一样计算各层的线性部分,z[ l ]是最后一层的z变量。z[ l ]=W[ l ] * a[l-1]+b[ l ],算出了z后,我们需要应用Softmax激活函数。它的作用是这样的: 我们要计算一个临时变量,我们把它叫做t。它等于ez[ l ]</sup>,这适用于每个元素。而这里的z[ l ],在上面这个例子中,维度是4x1的。四维向量t=ez[ l ],这是对所有元素求幂,t也是一个4x1维向量,然后输出a[ l ],基本上就是向量t,但是会归一化,使和为1。

换句话说,a[ l ]也是一个4x1维向量。而这个思维向量的第 i 个元素:

讲个例子:假设我们算出了z[ l ],这是一个四维向量。假设为:

我们要做的就是用这个元素取幂方法来计算t,所以:

接着利用计算器计算得到以下值:

如果把t的元素都加起来,把这四个数字加起来,得到176.3。最终:

看下图:
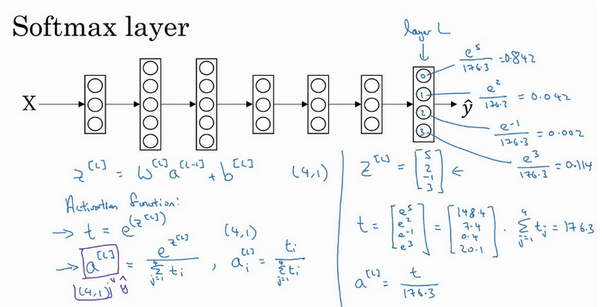
例如第一个节点,会输出e5/176.3=0.842。这样来说,对于这张图片,它是0类的概率就是84.2%。下个节点输出0.042,也就是4.2%的几率是1类。其它类别以这种规律推出。
神经网络的输出a[ l ],也就是y帽。是一个4x1维向量,如下:

所以这种算法通过向量z计算出总和为1的四个概率。
之前,我们的激活函数都是接受单行数值输入,例如Sigmoid和ReLu激活函数,输入一个实数,输出一个实数。Softmax激活函数的特殊之处在于,因为需要将所有可能的输出归一化,就需要输入一个向量,最后输出一个向量。
下面是分类的几个例子:
这是一个没有隐藏层的神经网络。他所做的就是z[1]=W[1] * x+b[1],而输出的a[ l ]=g(z[1]),就是Softmax激活函数。

上面三张图的C=3,下面三张图从左到右的C等于4、5、6。
这显示了Softmax分类器在没有隐藏层的情况下能够做到的事情,当然更深的神经网络会有x,然后是一些隐藏单元,以及更多隐藏单元等等,你就可以学习更复杂的非线性决策边界,来区分多种不同分类。
训练一个Softmax分类器
回忆我们之前举得例子,输出层计算的z[ l ]。我们有四个分类,z[ l ]可以是4x1维向量,我们计算了临时变量t。

如果我们的激活函数是Softmax,那么输出是这样的:
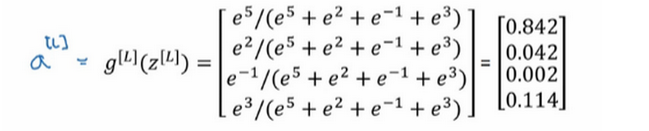
简单来说就是用临时变量t将它归一化,使总和为1。于是这就变成了a[ l ]。在这个向量z中,最大的元素是5。最大的概率是0.842。
Softmax这个是与所谓的hardmax对比,hardmax会把z变量变为[1 0 0 0]T,hardmax会观察z的元素,然后在z中最大元素的位置放上1,其它的输出都放0。
Softmax回归或Softmax激活函数将logistic激活函数推广到C类,而不仅仅是两类。而当C=2,那么的Softmax实际上变回了logistic回归,那么输出层将会输出两个数字。如果C=2的话,也许输出0.842和0.158,对吧?这两个数字加起来要等于1,因为它们的和必须为1,其实它们是冗余的,也许你不需要计算两个,而只需要计算其中一个,结果就是你最终计算那个数字的方式又回到了logistic回归计算单个输出的方式。
接下来我们来看怎样训练带有Softmax输出层的神经网络,具体而言,我们先定义训练神经网络使会用到的损失函数。举个例子,我们来看看训练集中某个样本的目标输出,真实标签是[0 1 0 0]T,用上一个视频中讲到过的例子,这表示这是一张猫的图片,因为它属于类1,现在我们假设你的神经网络输出的是 y帽,y帽是一个包括总和为1的概率的向量,y帽=[0.3 0.2 0.1 0.4]T,可以看到总和为1,这就是a[ l ]。对于这个样本神经网络的表现不佳,这实际上是一只猫,但却只分配到20%是猫的概率,所以在本例中表现不佳。
那么我们使用什么损失函数来训练这个神经网络?看下图:

注意在这个样本中,y1=y2=y3=0,因为这些都是0,只有y2=1,如果你看这个求和,所有含有值为0的yi的项都等于0,最后只剩下 -y2logy2帽,因为当你按照下标 j 全部加起来,所有的项都为0,除了j=2,因为y2=1,所以它就等于 -logy2帽。

这就意味着,如果你的学习算法试图将它变小,因为梯度下降法是用来减少训练集的损失的,要使它变小的唯一方式就是使 -logy2帽变小,要想做到这一点,就需要使 y2帽 尽可能大。也就是[0.3 0.2 0.1 0.4]T中的第二个元素。
接下来看看,我们在有Softmax的输出层如何实现梯度下降法。输出层会计算z[1],它是C x 1维的。在上个例子中,是4 x1维的。然后用Softmax激活函数来得到a[ l ]或者y帽。然后计算出损失。反向传播的关键步骤是这个表达式dz[ l ]=y帽-y。我们用y帽这个4x1向量减去y这个4x1向量。这是对z[ l ]的损失函数的偏导数dz[ l ]=∂J/∂z[ l ],然后开始反向传播的过程,计算整个神经网络中所需要的所有导数。

