开始前的准备
本文用到的库:numpy、sklearn、matplotlib
另外,我们还要借助一下吴恩达老师的工具函数testCases.py 和 planar_utils.py。地址)
testCases:提供测试样本来评估我们的模型。
planar_utils:提供各种有用的函数。
这两个文件的函数就不具体阐述了,有兴趣的自己研究去吧。
导入必要的库
1 | import numpy as np |
数据集介绍
1 | #X是训练集,Y是测试集 |
数据集的说明:
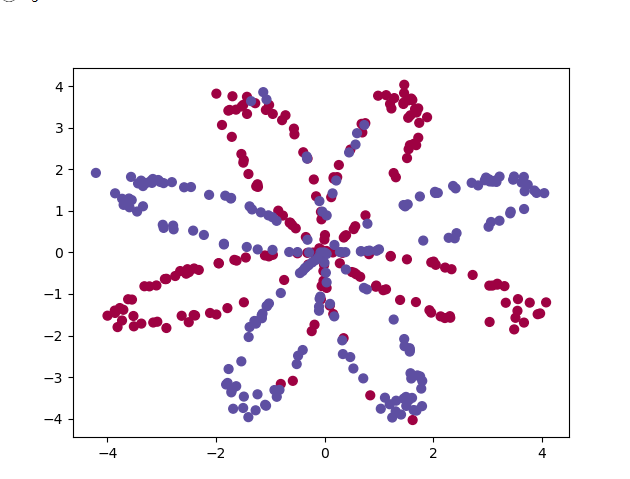
- X是维度为(2, 400)的训练集,两个维度分别代表平面的两个坐标。
- Y是为(1, 400)的测试集,每个元素的值是0(代表红色),或者1(代表蓝色)
利用 matplotlib 进行数据的可视化操作,这是一个由红点和蓝色的点构成的类似花状的图像
1 | # np.squeeze()函数对矩阵进行压缩维度,删除单维度条目,即把shape中为1的维度去掉 |
构建神经网络模型

对于某个样本x^[i]:

成本函数J:

接下来我们要用代码实现神经网络的结构,步骤大致如下: 1. 定义神经网络结构 2. 随机初始化参数 3. 不断迭代: - 正向传播 - 计算成本函数值 - 利用反向传播得到梯度值 - 更新参数(梯度下降)
定义神经网络的结构
主要任务是描述网络各个层的节点个数
1 | def layer_sizes(X, Y): |
随机初始化参数
参数W的随机初始化是很重要的,如果W和b都初始化成0,那么这一层的所有单元的输出值都一样,导致反向传播时,所有的单元的参数都做出完全相同的调整,这样多个单元的效果和只有一个单元的效果是相同的。那么多层神经网络就没有任何意义。为了避免这样的情况发生,我们会把参数W初始化成非零。
另外,随机初始化W之后,我们还会乘上一个较小的常数,比如 0.01 ,这样是为了保证输出值 Z 数值都不会太大。为什么这么做?设想我们用的激活函数是 sigmoid 或者 tanh ,那么,太大的 Z 会导致最终 A 会落在函数图像中比较平坦的区域内,这样的地方梯度都接近于0,会降低梯度下降的速度,因此我们会将权重初始化为较小的随机值。
1 | def initialize_parameters(n_x, n_h, n_y): |
循环迭代
实现正向传播
1 | def forward_propagation(X, parameters): |
计算成本函数J
1 | def compute_cost(A2, Y, parameters): |
利用正向传播函数返回的cache,我们可以实现反向传播了。
实现反向传播

说明:
我们使用的 g^[1] () 是 tanh ,并且 A1 = g^[1] ( Z^[1] ) ,那么求导变形后可以得到 g‘ ^[1] ( Z^[1] ) = 1-( A^[1] )^2 用python表示为: 1 - np.power(A1, 2)
我们使用的 g^[2] () 是 sigmoid ,并且 A2 = g^[2] ( Z^[2] ) ,那么求导变形后可以得到 g‘ ^[2] ( Z^[2] ) =A^2 - Y
1 | def backward_propagation(parameters, cache, X, Y): |
说明
1、计算db^[1]和db^[2]时的程序代码的sum函数的第二个参数 axis=1 表示水平相加求和。
2、 keepdims=True是为了保持矩阵的shape属性值是我们熟悉的()中有两个数字的形式,例如(1, m),(4, m)等,如果不加上可能得到的是奇怪的(1, ),(4, )这样的形式。
更新参数
利用上面反向传播的代码段获得的梯度去更新 (W1, b1, W2, b2):
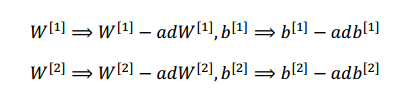
式子中 α 是学习率,较小的学习率的值会降低梯度下降的速度,但是可以保证成本函数 J 可以在最小值附近收敛,而较大的学习率让梯度下降速度较快,但是可能会因为下降的步子太大而越过最低点,最终无法在最低点附近出收敛。
本篇博客选择1.2作为学习率
1 | def update_parameters(parameters, grads, learning_rate=1.2): |
构建完整的神经网络模型
1 | def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False): |
对样本进行预测
我们约定 预测值大于0.5的之后取1,否则取0:

对一个矩阵M而言,如果你希望它的每个元素 如果大于某个阈值 threshold 就用1表示,小于这个阈值就用 0 表示,那么,在python中可以这么实现:M_new = (M > threshold)
1 | def predict(parameters, X): |
利用模型预测
1 | # 利用含有4个神经元的单隐藏层的神经网络构建分类模型 |
尝试换一下隐藏层的单元个数
1 | plt.figure(figsize=(16, 32)) |
换数据集
1 | # Datasets |

