主干网络介绍
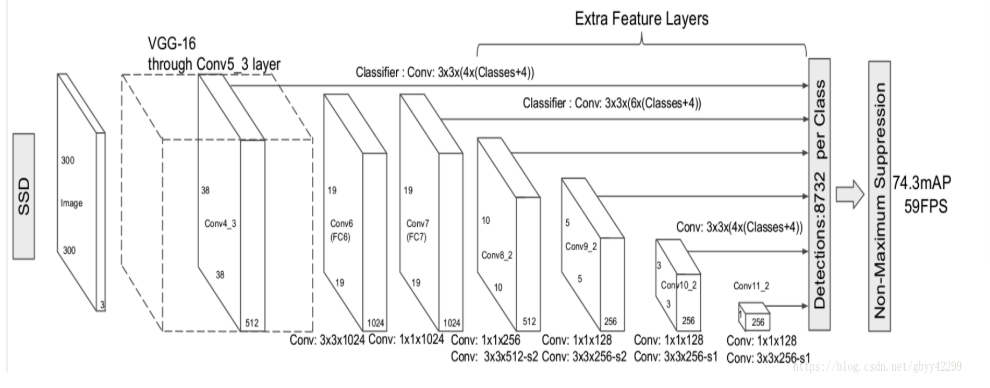
主干网络原始作者采用的VGG16,我们也可以将其他神经网络作为主干网络。例如:ResNet、MobileNets等
输入300300的image,将VGG16网络FC6、FC7换成conv6和conv7,同时将池化层变为stride=1,pool_size=3\3,这样做的目的是为了不减少feature map size,为了配合这种变化,conv6会使用扩张率为6的带孔卷积。
带孔卷积:就是不增加参数数量和model复杂度的情况下扩大卷积的感受域,用dialation_rate设置扩张率。类似于形态学操作中的膨胀。具体看目标检测常用名词)
接着然后移除dropout层和fc8层,并新增conv7,conv8,conv9,conv10,conv11,在检测数据集上做finetuing。其中VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是38×38,但是该层比较靠前,其norm较大,所以在其后面增加了一个L2 Normalization层(参见ParseNet),以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma。
多尺度feature map预测
多尺度feature map预测,也就是在预测的时候,在接下来预测的时候,针对接下来六个不同的尺寸进行预测。如下图的六条连线,分别是38*38、19*19、10*10、5*5、3*3、1*1。将这六个不同尺度的feature map分别作为检测、预测层的输入,最后通过NMS进行筛选和合并。
对于六种不同尺度的网络,我们通常使用pooling来降采样。对于每一层的feature map,我们输入到相应的预测网络中。而预测网络中,我们会包括Prior box的提取过程。Prior box对应Fast R-CNN中Anchor的概念,也就是说,在Prior box中,feature map上的每一个点都作为一个cell(相当于Anchor)。以这个cell为中心,按照等比的放缩,找到它在原始图片的位置。接着以这个点为中心,提取不同尺度bounding box。而这些不同尺度的bounding box就是Prior box。然后对于每一个Prior box,我们通过和真值比较,就能够拿到它的label。对于每一个Prior box,我们都会分别预测它的类别概率和坐标(x,y,w,h)。也就是说,对于每一个cell,我们会将它对应到不同的Prior box,分别来预测当前这个Prior box所对应当前这个类别的概率分布和坐标。
对Prior Box的具体定义:
这里我们假设Prior Box的输入是m*n维的feature map。
如果每一个点都作为cell,那就会有mn个cell。接着每个cell上生成固定尺寸和不同长宽比例的box。每个cell对应k个bounging box,每个bounding box预测c个类别分数和4个偏移坐标。其中c个类别分数实际上是当前bounding box所对应的不同类别的概率分布。如果输入大小为m\n,那就会输出(c+4)*k*m*n。其中尺寸(scale)和比例(ratio)是超参数。
接下来我们看看Prior box是怎么生成的:

每个feature map上的点定义了六种长宽比的default box。也就是说,最后对于每一个anchor都会获得六个不同尺寸和长宽比的default box。对于3838层,每个feature map上的点,我们都会提取4个default box作为prior box。对于19\19层、10*10层、5*5,提取6个default box也就是全部都是prior box。而3*3、1*1提取4个default作为prior box。所以最后得到8732个prior box(38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4)。prior box就是选择的default box。尺寸和比例都是可以通过SSD的配置文件进行配置,后面实战详解。
对default box进行筛选成为prior box:每一个feature map cell不是k个default box都取,prior box与GT box(Ground Truth box)做匹配,IOU>阈值为正样本。IOU<阈值 为负样本。介于正样本和负样本中间阈值的default box去掉。
SSD系列算法优化及扩展
SSD算法对小目标不够鲁棒,原因最主要是浅层feature map的表征能力不够强。
DSSD:
DSSD相当原来的SSD模型主要作了两大更新。一是替换掉VGG,而改用了Resnet-101作为特征提取网络并在对不同尺度feature maps特征进行default boxes检测时使用了更新的检测单元;二则在网络的后端使用了多个deconvolution layers以有效地扩展低维度信息的contextual information,从而有效地提高了小尺度目标的检测。
下图为DSSD模型与SSD模型的整体网络结构对比:

DSOD:
SSD+DenseNet=DSOD
DSOD可以从0开始训练数据,不需要预训练模型。
FSSD:
借鉴了FPN的思想,重构了一组pyramid feature map(金字塔特征),使得算法的精度有了明显特征,速度也没有下降很多。具体是把网络中某些feature调整为同一size再contact(连接),得到一个像素层,以此层为base layer来生成pyramid feature map,作者称之为Feature Fusion Module。
Feature Fusion
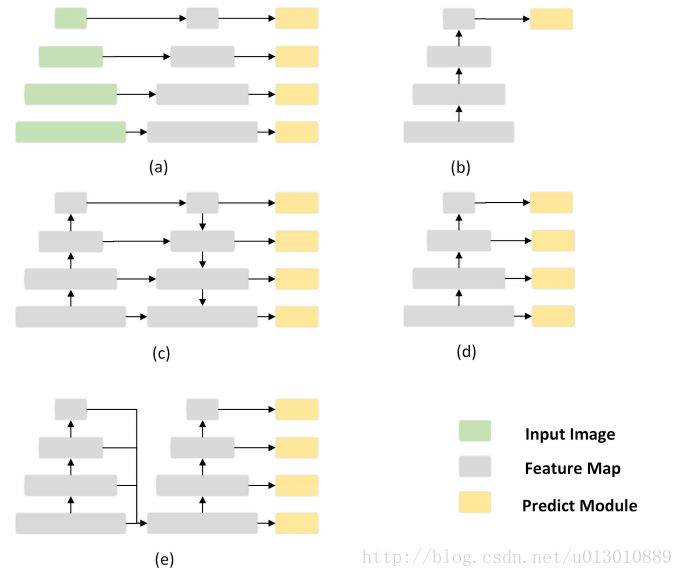
对上面图的解读:
(a) image pyramid
(b) rcnn系列,只在最后一层feature预测
(c) FPN,语义信息一层传递回去,而且有很多相加的计算
(d) SSD,在各个level的feature上直接预测,每个level之间没联系
(e) FSSD的做法,把各个level的feature concat,然后从fusion feature上生成feature pyramid
FSSD网络结构:

RSSD:
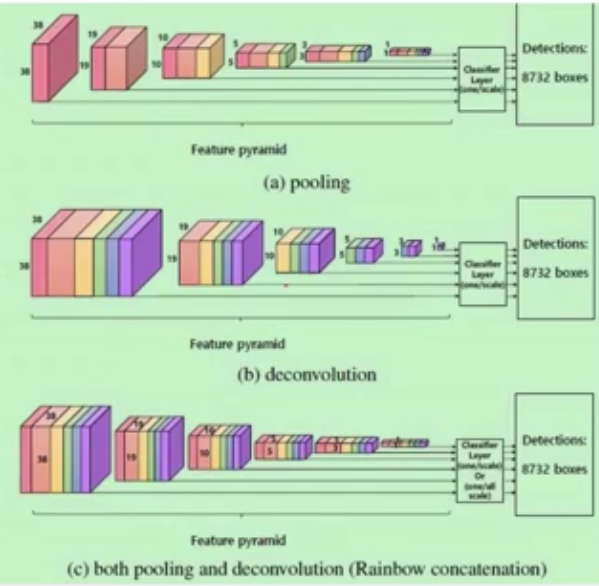
rainbow concatenation方式(pooling加deconvolution)融合不同层的特征,再增加不同层之间feature map关系的同时也增加了不同层的feature map个数。这种融合方式不仅解决了传统SSD算法存在的重复框问题,同时一定程度上解决了small object的检测问题。