张量
张量可以说时Tensorflow的标志。因为整个框架的名称Tensorflow就是张量流的意思。
在tensorflow中把数据称为张量(tensor)。每个tensor包含了类型(type)、阶(rank)和形状(shape)。
tensor类型
下面把tensor类型和python的类型放在一起比较。

tensor阶
张量的阶:相当于数组的维度。 但张量的阶和矩阵的阶并不是同一个概念,主要是看有几层中括号。例如:对于一个传统的三阶矩阵a=[[1,2,3],[4,5,6],[7,8,9]]。在张量中的阶数表示为2阶(因为它有两层中括号)

tensor形状
shape用于描述张量内部的组织关系。“形状”可以通过Python中的整数列表或元祖来表示,也可以Tensorflow中的相关形状函数来表示。
举例:一个二阶张量a=[[1,2,3],[4,5,6]]形状是两行三列,描述为(2,3)。
tensorflow中张量形状分为动态形状和静态形状,其在于有没有生成一个新的张量数据。静态形状的修改不能跨维度修改
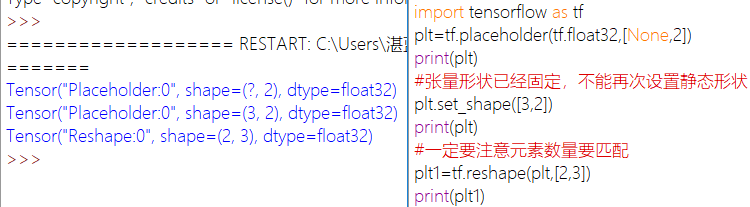
相关操作
张量的相关操作包括类型转换、数值操作、形状变换、数据操作。
类型转换

数值操作
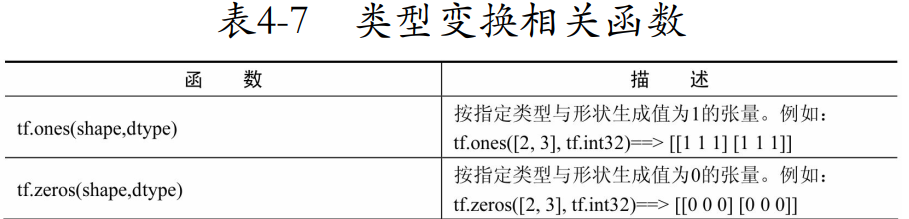
tf.ones_like和tf.zeros_like的描述错了,应该分别生成1和0

形状变换
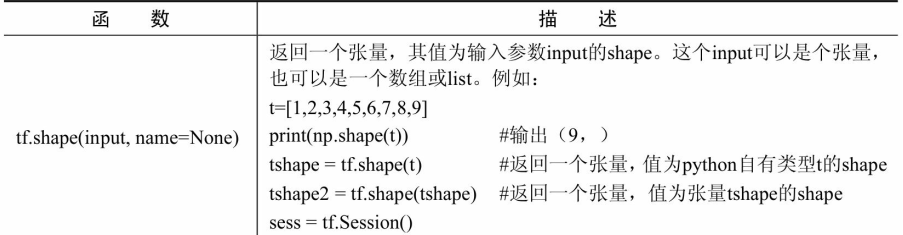



数据操作



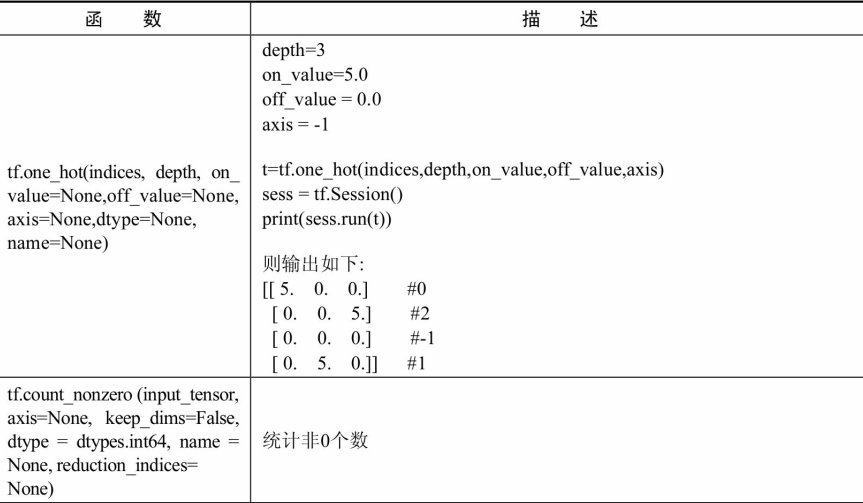
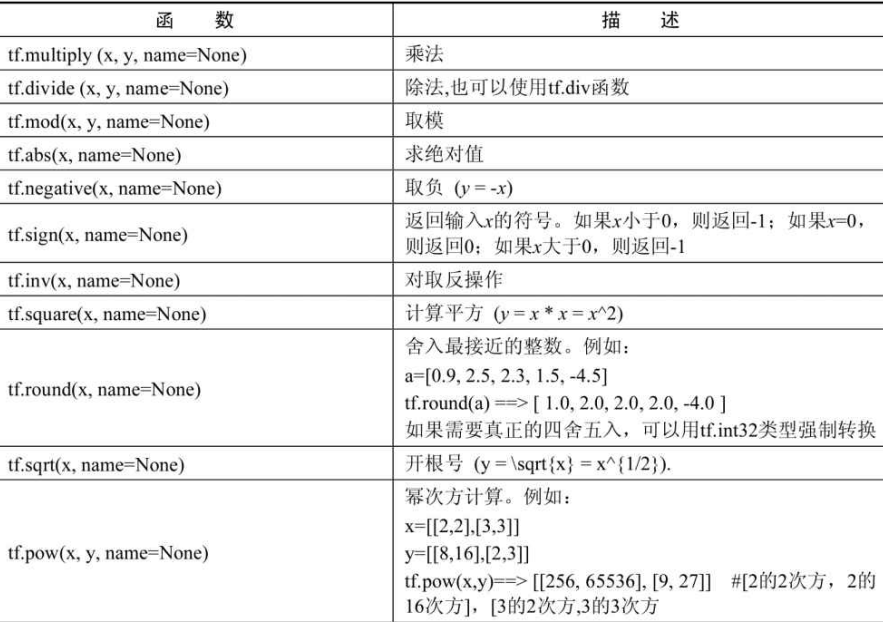
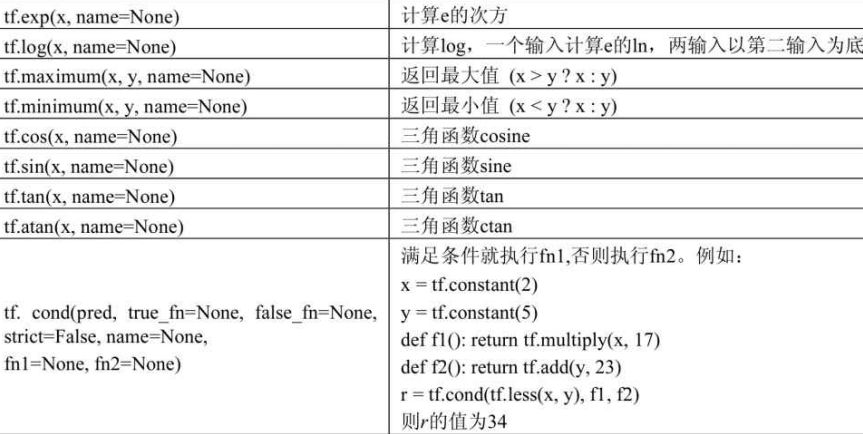
算术运算函数

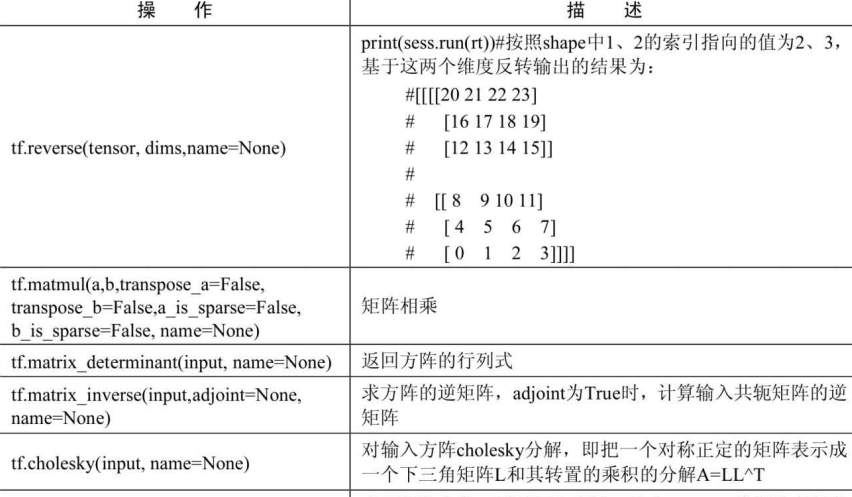
矩阵相关函数



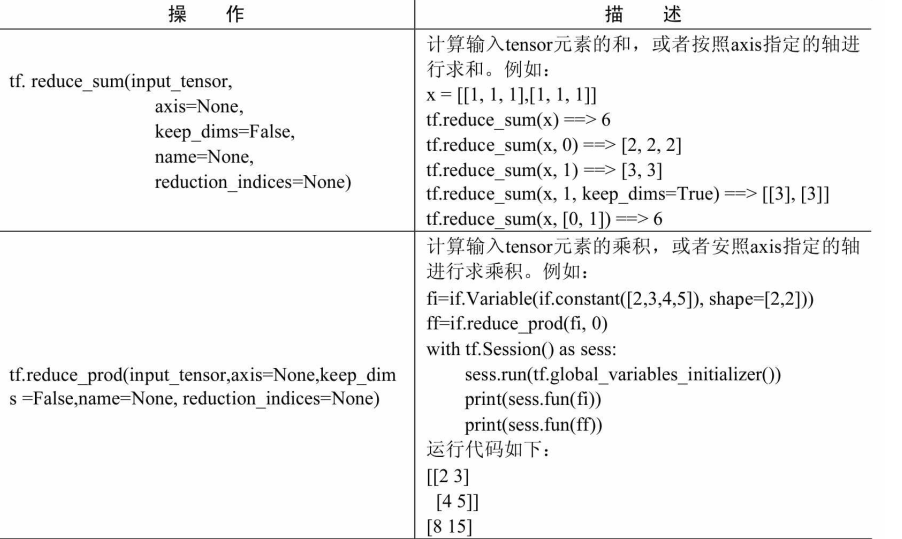
规约计算
规约计算的操作都会有降维的功能,在所有reduce_xxx系列操作函数中,都是以xxx的手段降维,每个函数都有axis这个参数,即沿某个方向,使用xxx方法对输入的Tensor进行降维。
axis的默认值是None,即把input_tensor降到0维。即一个数。对于二维input_tensor而言,axis=0,则按列计算。axis=1,则按行计算。
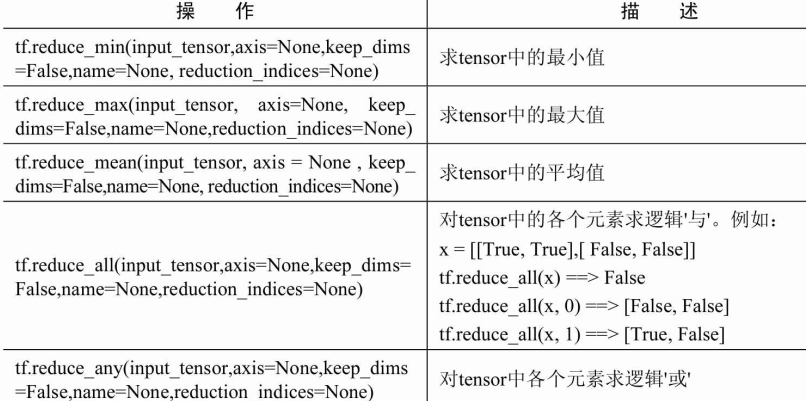
tf.reduce_mean()
函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。

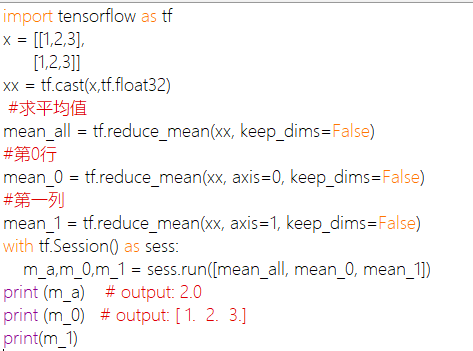
如果想设置为原来向量的维度,keep_dims=True。
分割
分割操作是tensorflow不常用的操作,在复杂的网络模型里偶尔才会用到。
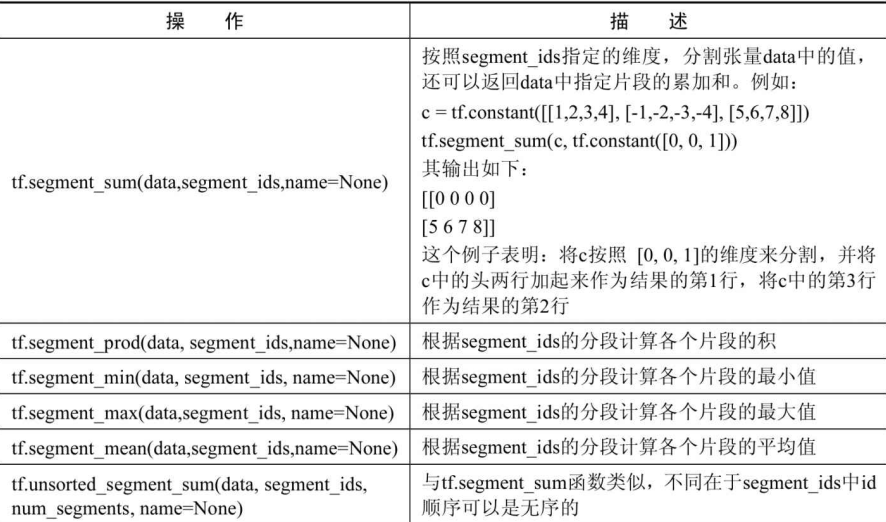
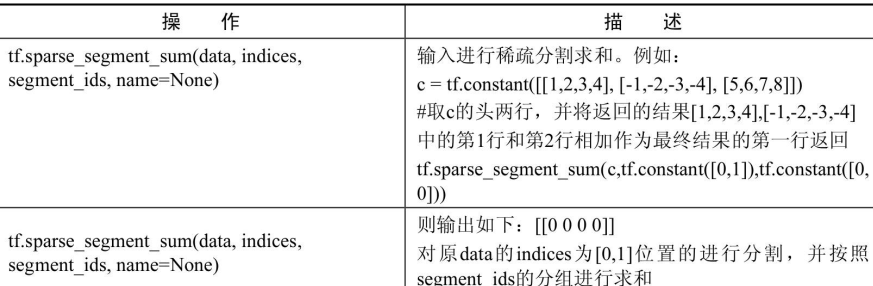
图
整个程序的结构称为图(graph),可以把图看作一个计算任务。
一个Tensorflow程序默认是建立一个图的,除了系统自动建图外,还可以自主建图。
建立图

1 | import tensorflow as tf |
运行上面代码,得出结果如下:

c是刚开始的默认图中建立的,所以图的打印值就是原始的默认图的打印值。然后使用tf.Graph函数建立了一个图g,并且在新建的图里添加变量,可以通过变量的“.graph”获得所在的图。在新图g的作用域外,使用tf.get_default_graph又获得了原始的默认图,接着又使用tf.reset_default_graph函数,相当于重新建立一张图来代替原来的默认图。
注意:在使用tf.reset_default_graph函数时必须保证当前图的资源已经全部释放,否则会报错。
获取张量
在图里可以通过名字得到其对应的元素,例如get_tensor_by_name可以获得图里面的张量。在上面的代码的基础上加上下面这段代码:
1 | print(c1.name) |
常量c1是在一个子图g中建立的。with tf.Graph()、as_default()代码表示使用tf.Graph函数来创建一个图,并在其上面定义op。
获取节点操作
获取节点操作op的方法是get_operation_by_name。
1 | import tensorflow as tf |
打印了一堆信息,看不懂。。。
获取元素列表
如果想看图中的全部元素,可以使用get_operations函数来实现。
1 | tt2=g.get_operations() |
有多少个常量,就打印多少条信息。
获取对象
前面是根据名字来获取信息,还可以根据对象来获取对象。使用tf.Graph.as_graph_element(obj,allow_tensor=True,allow_operation=True)函数,即传入的是一个对象,返回一个张量或是一个op。
1 | tt3=g.as_graph_element(c1) |
看上述代码对tt3的打印来看,变量tt3所指的张量名字为Const0。而在获取张量那小节可以看到量名c1所指向的真实张量名字也为Const0。这表明:函数as_graph_element获得了c1的真实张量对象,并赋给了变量tt3。
动态图(Eager)
动态图是相对于静态图而言的。所谓的动态图是指在Python中代码被调用后,其操作立即被执行的计算。其与静态图最大的区别是不需要使用session来建立会话了。即:在静态图中,需要在会话中调用run方法才可以获得某个张量的具体值,而在动态图中,直接运行就可以得到具体值。
动态图是在Tensorflow1.3版本之后出现的。启动动态图只需要在程序的最开始处加上两行代码
1 | import tensorflow.contrib.eager as tfe |
上面这两行代码的作用就是开启动态图计算功能。例如:调用tf.matmul时,将会立即计算两个数相乘的值,而不是op。
在创建动态图的过程中, 默认也建立了一个session。 所有的代码都在该session中进行, 而且该session具有进程相同的生命周期。 这表明一旦使用动态图就无法实现静态图中关闭session的功能。 这便是动态图的不足之处: 无法实现多
session操作。 如果当前代码只需要一个session来完成的话, 建议优先选择动态图Eager来实现
会话
运算程序的图称为会话(Session)。一次只能运行一个图
会话的作用:1、运行图的结构 2、分配资源运算 3、掌握资源
会话需要进行资源释放,需要run后进行close。否则可以使用with作为上下文管理器

可以在会话当中指定图去运行
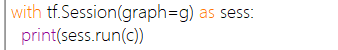
sess.run(fetches,feed_dict=None,graph=None)启动整个图。
用来运行op和计算tensor

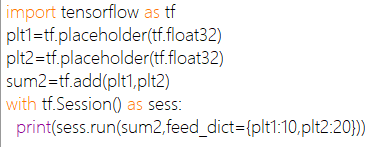
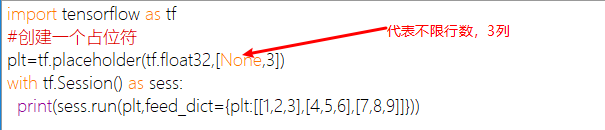
feed_dict常与placeholder(占位符)一起使用

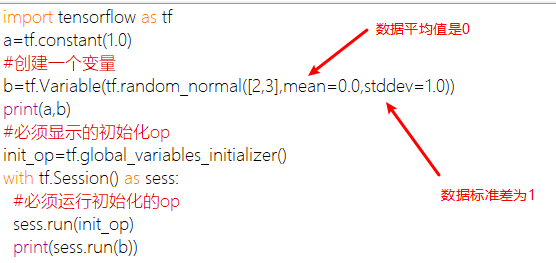
变量:tensorflow中的变量也是一种op,是一种特殊的张量能够进行存储持久化,它的值就是张量,默认被训练。其中有个trainable参数默认为True,如果改为False,变量将不再变化。
图的可视化(tensorboard)
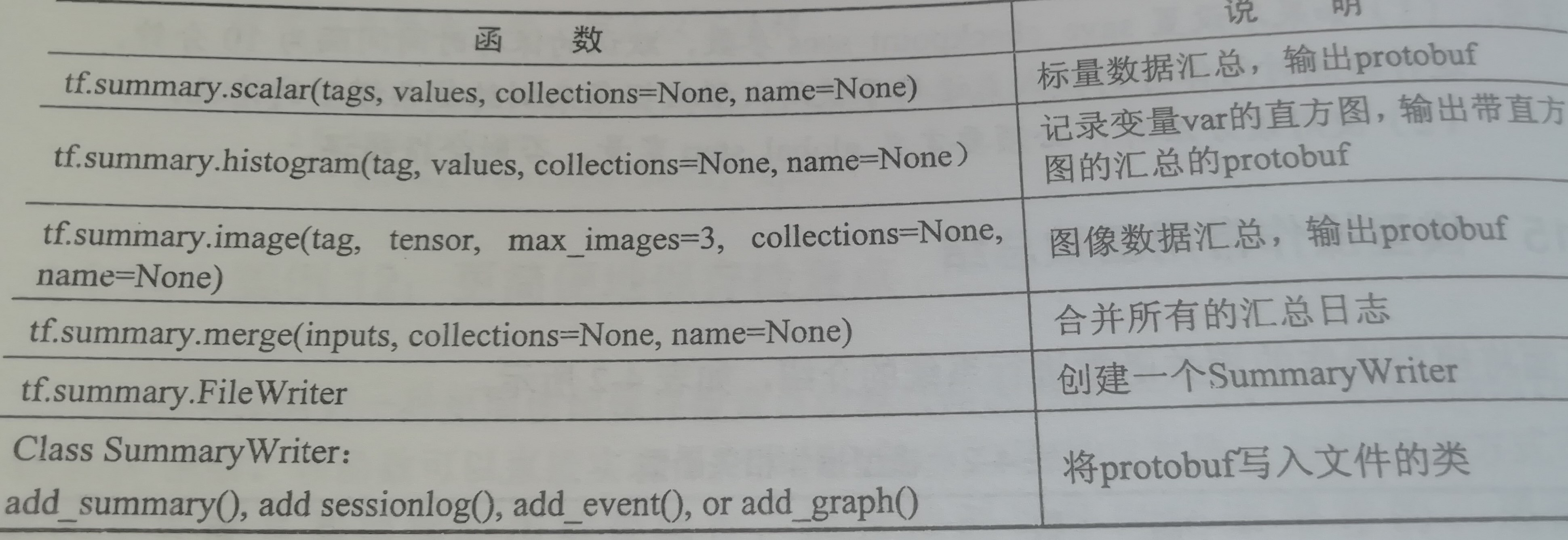
tensorflow提供了一个可视化工具TensorBoard,它可以把训练过程中的各种绘制数据展示出来,包括标量(Scalers)、图片(Images)、音频(Audio)、计算图(Graph)、数据分布、直方图(Histograms)和嵌入式向量。可以通过网页来观察模型的结构和训练过程中各个参数的变化。
当然,TensorBoard不会自动把代码展示出来,其实它是一个日志展示系统,需要在session中运算图时,将各种类型的数据汇总并输出到日志文件中。然后启动TensorBoard服务,TensorBoard读取这些日志文件,并开启6006端口提供web服务,让用户可以在浏览器中查看数据。
1 | import tensorflow as tf |
运行上面代码显示的内容和以前一样没什么变化,在代码的同级目录下多了一个文件夹,里面还有个文件夹。文件夹内有个文件。首先在命令行下pip安装tensorboard,接着在这个文件的上级路径下,输入下面命令

双引号中间填绝对路径,注意不要出现中文和空格。
注意:1、浏览器最好使用谷歌。2、在命令行里启动TensorBoard时,一定要先进入到日志所在的上级目录下,否则打开的页面找不到创建好的信息。
深度学习中的线性回归:
1 | import tensorflow as tf |
如果后面的几个数据的迭代得出的结果是一样的,那么证明该模型已经梯度下降到最低点。此时应该把学习率调小。
保存和载入模型
保存模型
首先需要建立一个saver,然后再session中通过saver的save即可将模型保存起来。
1 | #生成saver |
运行以上代码后,在代码的同级目录下,生成几个文件。如图:

载入模型
1 | saver=tf.train.Saver() |
保存模型的其它方法
Saver还可以指定存储变量名字与变量的对应关系
1 | saver=tf.train.Saver({"weight":W,"bias":b}) |
上面这种写法代表将W变量的值放到weight名字中,类似的写法还有以下两种:
1 | #放到一个list里 |
模型内容
虽然模型已经保存了,但是仍然对我们不透明。下面代码将模型内容打印出来,看看保存了那些东西
1 | from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file |
添加保存检查点
保存模型并不限于在训练之后,在训练之中也需要保存,因为tensorflow训练模型时难免会出现中断的情况。我们希望能够将幸苦得到的中间参数保留下来,否则下次又要重新开始。这种,在训练中保存模型,习惯上称为保存检查点。
PS:我感觉预训练模型和这个一样
此时用到saver的另一个参数,max_to_keep。表明最多只保存检查点文件的个数。
saver=tf.train.Saver(max_to_keep=1),代表在迭代过程中只保存一个文件。这样,在循环训练模型中,新生成的模型就会覆盖以前的模型。
下面两种方法可以快速获取到检查点文件:
1 | #第一种 |


