这几年,python大火。其中的一个原因是python的库特别多,而且封装非常好。接下来我来总结以下我用过的一些库,虽然都不是很大的库,但还是有用的。
json
json主要执行序列化和反序列化的功能,通过Python的json模块,可以将字符串形式的json数据转化为字典,也可以将Python中的字典数据转化为字符串形式的json数据。
通过json字符串转为字典 json.loads
字典转换为json:json.dumps
json.loads()、dumps解码python json格式
json.load、dump加载json格式文件

pickle使用方法与json一样
区别:
json是可以在不同语言之间交换数据的,而pickle只在python之间使用。
json只能序列化最基本的数据类型,而pickle可以序列化所有的数据类型,包括类,函数都可以序列化。
hashlib
该模块提供了常见的摘要算法。如MD5,SHA1……摘要算法又称哈希算法、散列算法,通过一个函数,把任意长度的数据转换为一个长度固定的数据串。

摘要算法是一个单向函数,通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是发现原始数据是否被改动过。计算f(data)很容易,但通过digest反推data却非常困难,对原始数据做一个字节的修改,都会导致计算出来的摘要不同。
string
string.digits:包含数字0-9的字符串
string.letters:包含所有字母(大写或小写)的字符串
string.lowercase:包含所有小写字母的字符串
string.printable:包含所有可打印字符的字符串
string.punctuation:包含所有标点的字符串
string.uppercase:包含所有大写字母的字符串
string.ascii_letters和string.digits方法,其中ascii_letters是生成所有字母,从a-z和A-Z,digits是生成所有数字0-9.

词云

decimal
如果期望获得更高的精度(并且愿意牺牲掉一些性能),可以使用decimal模块。

fractions
模块可以用来处理涉及分数的数学计算问题

copy
完成深拷贝和浅拷贝
is和==的区别:==是看值,is看是否指向同一个
浅拷贝:拷贝内容的地址

深拷贝:开发另一片空间存放要拷贝的内容

copy会判断数据类型是否为可变类型,如元祖为不可变类型,则只会完成浅拷贝。
fileinput
可以快速对一个或多个文件进行循环遍历
fileinput.input([files[, inplace[, backup[, mode[, openhook]]]]]])功能:生成FileInput模块类的实例。能够返回用于for循环遍历的对象。注意:文件名可以提供多个
inplace:是否返回输出结果到源文件中,默认为零不返回。设置为1时返回。
backup:备份文件的扩展名
mode:读写模式。只能时读、写、读写、二进制四种模式。默认是读
openhook:必须是一个函数,有两个参数,文件名和模式。返回相应的打开文件对象
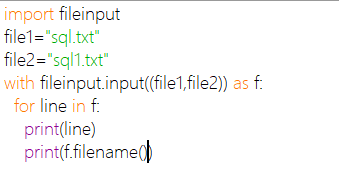
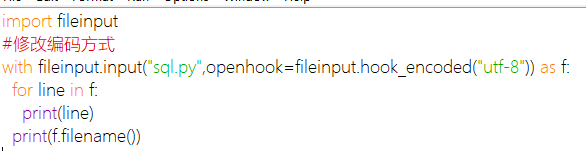
fileinput.filename():返回当前正在读取的文件的名称。在读取第一行之前,返回None。
fileinput.fileno():返回当前文件的整数“文件描述符”。如果没有打开文件(在第一行之前和文件之间),则返回-1。
fileinput.lineno():返回刚读过的行的累计行号。在读取第一行之前,返回0。读取完最后一个文件的最后一行后,返回该行的行号。
fileinput.filelineno():返回当前文件中的行号。在读取第一行之前,返回0。读取完最后一个文件的最后一行后,返回该文件中该行的行号。
fileinput.isfirstline():如果刚刚读取的行是其文件的第一行,则返回true,否则返回false。
fileinput.isstdin():如果读取了最后一行sys.stdin,则返回true,否则返回false。
fileinput.nextfile():关闭当前文件,以便下一次迭代将读取下一个文件的第一行(如果有的话); 未从文件中读取的行将不计入累计行数。直到读取下一个文件的第一行之后才会更改文件名。在读取第一行之前,此功能无效; 它不能用于跳过第一个文件。读取完最后一个文件的最后一行后,此功能无效。
fileinput.close()关闭序列
subprocess:
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。Popen()建立子进程的时候改变标准输入、标准输出和标准错误,并可以利用subprocess.PIPE将多个子进程的输入和输出连接在一起,构成管道(pipe)
subprocess.call():父进程等待子进程完成,返回退出信息(returncode,相当于Linux exit code)
subprocess.check_call():父进程等待子进程完成,返回0,检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性,可用try…except…来检查
subprocess.check_output():父进程等待子进程完成,返回子进程向标准输出的输出结果,检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性和output属性,output属性为标准输出的输出结果,可用try…except…来检查。
subprocess.Popen(),以下为参数:
args:shell命令,可以是字符串,或者序列类型,如list,tuple。
bufsize:缓冲区大小,可不用关心
stdin,stdout,stderr:分别表示程序的标准输入,标准输出及标准错误
shell:与上面方法中用法相同
cwd:用于设置子进程的当前目录
env:用于指定子进程的环境变量。如果env=None,则默认从父进程继承环境变量
universal_newlines:不同系统的的换行符不同,当该参数设定为true时,则表示使用\n作为换行符
常用方法:
poll() : 检查子进程状态
kill() : 终止子进程
send_signal() :向子进程发送信号
terminate() : 终止子进程
communicate:从PIPE中读取PIPE的文本,该方法会阻塞父进程,直到子进程完成
常用属性:pid:子进程的pid,returncode:子进程的退出码。

