pandas也是一个非常强大的库,所以我也只是总结了我用到的方法。
pandas常用的数据类型:1、Series 一维 带标签的数组(标签就是索引)2、DataFrame 二维 Series的容器
Series:
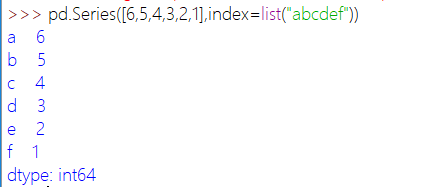
通过列表创建Series:

索引可以指定,默认从0开始:
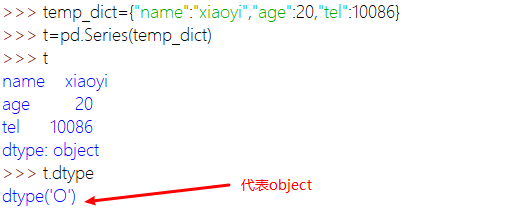
通过字典创建Series:可以通过astype修改类型
取值:


可以将条件和value、index配合使用:
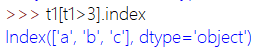
pandas读取外部数据:
read_csv:读取CSV文件
read_excel:读取excel文件
其他文件类似
DataFrame
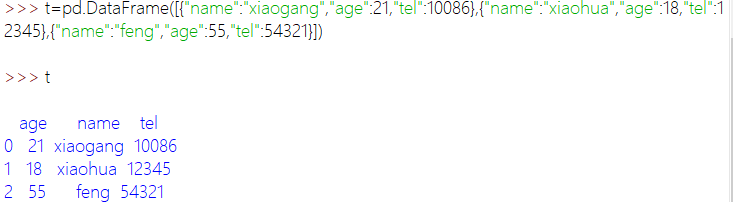
通过列表创建:
通过数组创建:

通过字典创建:

DataFrame的基础属性:
shape :行数 列数
dtypes:列数据类型
ndim:数据维度
index:行索引
columns:列索引
values:对象值
DataFrame的方法:
head(n):显示头n行。默认是前5行
tail(n):显示尾n行。
info():行数,列数,列索引,列非空值个数,列类型,内存占用
describe():计数 均值 标准差 最大值 四分位数 最小值

DataFrame排序:sort_values()。通过设置by来确定排序的key。设置ascending确定升序or降序。

DataFrame的取值:
方括号写数字,表示取行。对行进行操作。根据实际情况写
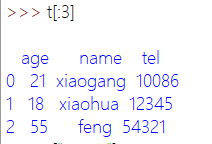
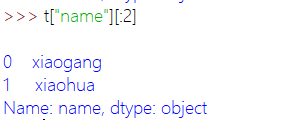
对列进行操作:

配合使用:
loc:DataFrame通过标签索引获取行数据


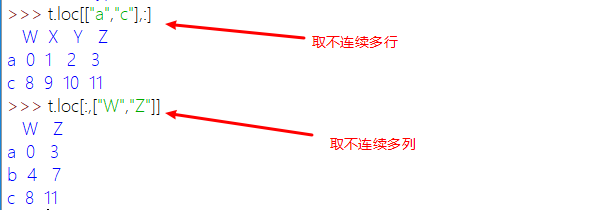
根据多个索引取多个对应的值:

iloc:DataFrame通过位置获取列数据。与ioc类似,只是将索引换成数字。
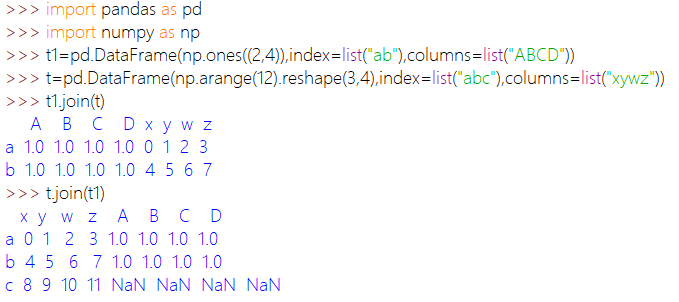
数组合并:
1、join 按行索引合并
2、merge按列索引进行合并 on指定按哪一列合并 how:合并方式 inner(交集,默认) outer(并集) left(左边为准,NaN补全) right(右边为准,NaN补全)

如果列索引不同。可以left_on和right_on指定左边、右边DataFrame的合并列。

另一种写法:
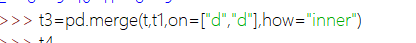
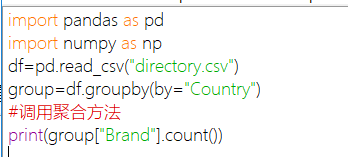
分组:groupby(by) by:通过什么分组,可以设置多个条件分组


聚合:count 计算数量
sum 求和
mean 求平均值
median 求中位数
std、var 求标准差和方差
min、max 求最大和最小值
DataFrame的索引和复合索引:
简单的索引操作:
获取index:df.index
指定index:df.index=[“”,””]

同理可得指定columns:df.columns=[“ “,” “]

重新设置index:df.reindex()

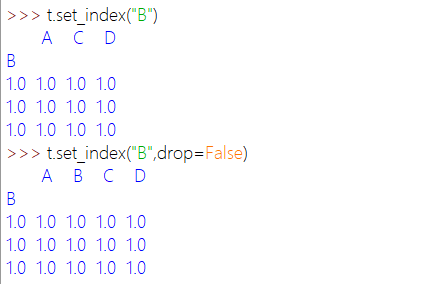
指定某一列成为index:df.set_index()。drop决定是否保留设定的列
可以设定多个列成为index:

返回index的唯一值:df.set_index().index.unique()

时间序列:date_range(start,end,period,freq) 生成一段时间范围。start和end表示范围,periods表示个数,freq表示频率(年、月、天)


频率类型:

时间段:PeriodIndex

重采样resample:指的是将时间序列从一个频率转化为另一个频率进行处理的过程。将高频率数据转化为低频率数据为降采样。低频率数据转化为高频率为升采样。

判断数据是否为NaN:
pd.isnull() pd.notfull()
在DataFrame中对缺失数据(NaN)的处理:
方式1:删除NaN所在的行列dropna(axis,how,inplace):how=”any”时一行(列)里有一个为nan就删。how=”all”时,一行全部为nan时才删。inplace为True,原地修改。False为False,不修改。
方式2:填充数据,fillna()
处理为0的数据:t[t==0]=np.nan
计算平均值时:nan不参与计算,0参与

