多进程:multiprocessing模块

os.getpid()获取当前进程的id os.getppid()获取父进程的id
大量启动子进程,可以用进程池pool批量创建子进程。可以通过processes改变创建的进程数目。

apply_async(func[, args=()[, kwds={}[, callback=None]]])该函数用于传递不定参数,非阻塞且支持结果返回进行回调。
将函数添加到进程池:

map(func, iterable[, chunksize=None]):Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到返回结果。 注意,虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
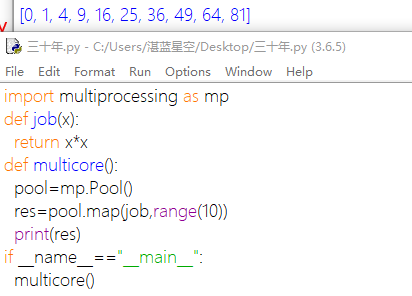
close():关闭进程池(pool),使其不在接受新的任务。
terminate():结束工作进程,不在处理未处理的任务。
join([timeout]):主进程阻塞等待子进程的退出,join方法必须在close或terminate之后使用。timeout表示等待最多时间。若超出,则会直接执行下列代码
Value、Array是通过共享内存的方式共享数据
Value:将一个值存放在内存中,
Array:将多个数据存放在内存中,但要求数据类型一致
Value:
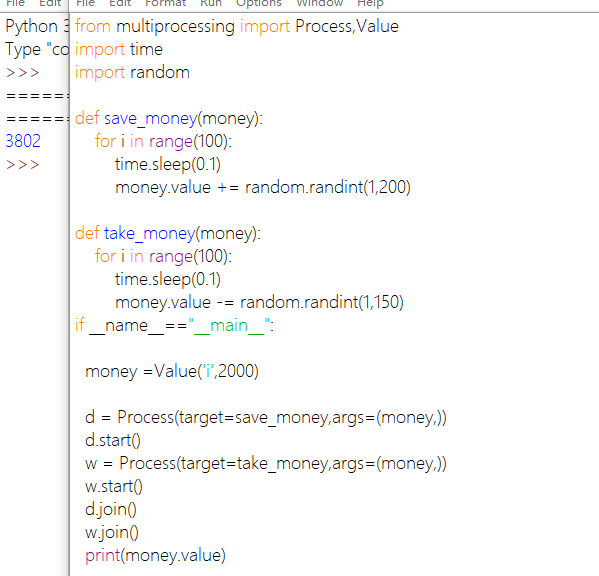
Array:两种情况
若为数字,表示开辟的共享内存中的空间大小,(Value表示为该空间绑定一个数值)
若为数组,表示在共享内存中存入数组

说明:三个0表示开辟的共享内存容量为3,当再超过3时就会报错。
Manager(Value、Array、dict、list、Lock、Semaphore等)是通过共享进程的方式共享数据。
进程间通信:Queue ,Pipe

使用方法和队列差不多
q.get_nowait():和get()差不多,不用等。
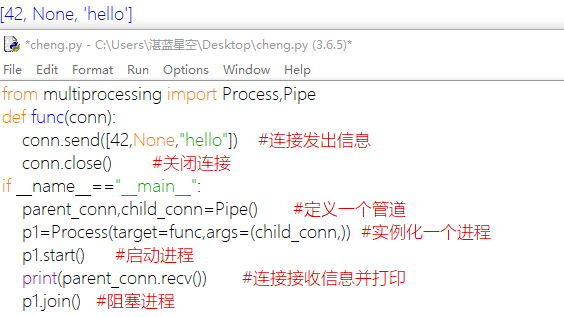
Pipe:Pipe可以是单向(half-duplex),也可以是双向(duplex)。我们通过mutiprocessing.Pipe(duplex=False)创建单向管道 (默认为双向)。一个进程从PIPE一端输入对象,然后被PIPE另一端的进程接收,单向管道只允许管道一端的进程输入,而双向管道则允许从两端输入。
这里的Pipe是双向的。
Pipe对象建立的时候,返回一个含有两个元素的表,每个元素代表Pipe的一端(Connection对象)。我们对Pipe的某一端调用send()方法来传送对象,在另一端使用recv()来接收。
生产者与消费者模式:在两者中找一个缓冲的东西(队列,缓冲池),解决数据生产方和数据处理方数据不分配的问题。
耦合:谁和谁的关系越强,耦合性就越强。耦合性越强,程序维护越难。
解耦的好处:哪块不合适,就改那块。


接上面:


