正则用法
原始字符串来表示正则表达式(就是在字符串前边加上 r)
正则表达式(不能随意添加空格,不然会改变原来含义):
元字符(不能匹配自身): . $ ^ ( ) { } [ ] $ + \ | *,
|:A | B 会匹配 A 或 B 中出现的任何字符。为了能够更加合理的工作,| 的优先级非常低。例如 Fish|C 应该匹配 Fish 或 C,而不是匹配 Fis,然后一个 ‘h’ 或 ‘C’。同样,我们使用 | 来匹配 ‘|’ 字符本身;或者包含在一个字符类中,像这样 [|]。
^:匹配字符串的起始位置。如果设置了 MULTILINE 标志,就会变成匹配每一行的起始位置。在 MULTILINE 中,每当遇到换行符就会立刻进行匹配。

$:匹配字符串的结束位置,每当遇到换行符也会离开进行匹配。

+:用于指定前一个字符匹配一次或多次
* : 匹配的是零次或多次

? :指定前一个字符匹配零次或者一次。

{m,n}(m和n都是十进制整数):它的含义是前一个字符必须匹配m次到n(包括n次)次之间

\A:只匹配字符串的起始位置。如果没有设置 MULTILINE 标志的时候,\A 和 ^ 的功能是一样的;但如果设置了 MULTILINE 标志,则会有一些不同:\A 还是匹配字符串的起始位置,但 ^ 会对字符串中的每一行都进行匹配。
\Z:只匹配字符串的结束位置

脱字符:^ ,例如[^5]会匹配任何字符 “5”之外的任何字符
[ ]他们指定一个字符类用于存放你需要的字符集合。可以单独列出需要匹配字符,也可以两个字符和一个横杆-指定匹配的范围。元字符在方括号中不会触发“特殊功能”,在字符类中,它们只匹配自身。
反斜杠 \:如果在反斜杠后边紧跟着一个元字符,那么元字符的“特殊功能”也不会被触发。例如你需要匹配符号[ 或 \,你可以在他们前面加上一个反斜杠,以消除他们的特殊功能:\[ ,\\\
匹配本机IP:
注意用小括号括住要重复的内容:

匹配ip(万能版):

零宽断言
零宽断言的意思是匹配宽度为0,满足一定条件的断言。用于查找在某些内容(不包括这些内容)之前或之后的东西。
零宽断言有四种:
先行断言
也叫零宽度正预测先行断言,格式是?=表达式,表示匹配表达式前面的位置

注意:先行断言的执行步骤是这样的先从要匹配的字符串中的最右端找到第一个ing。然后再匹配其前面的表达式,若无法匹配则继续查找第二个ing 再匹配第二个ing前面的字符串,若能匹配则匹配
后发断言
也叫零宽度正回顾后发断言,格式是?<=表达式,表示匹配表达式后面的位置

注意:后发断言的执行步骤是这样的:先从要匹配的字符串中的最左端找到第一个abc。然后再匹配其后面的表达式,若无法匹配则继续查找第二个abc 再匹配第二个abc后面的字符串,若能匹配则匹配
负向零宽先行断言
负向零宽先行断言 ,格式为?!表达式,\d{3}(?!\d):匹配三位数字,而且这三位数字的后面不能是数字

负向零宽后发断言

非捕获组和命名组
非捕获组的语法是 (?:…),这个 … 你可以替换为任何正则表达式。“捕获”的意思就是匹配的,普通的子组都是捕获组,因为它们能从字符串中匹配到数据
命名捕获组:格式为(?P\
1 | import re |
修改字符串
正则表达式使用以下方法修改字符串:

split(string[, maxsplit=0]):通过正则表达式匹配来分割字符串。如果在 RE 中,你使用了捕获组,那么它们的内容会作为一个列表返回。你可以通过传入一个 maxsplit 参数来设置分割的数量。如果 maxsplit 的值是非 0,表示至多有 maxsplit 个分割会被处理,剩下的内容作为列表的最后一个元素返回。

.sub(replacement,string[,count=0]):返回一个字符串,这个字符串从最左边开始,所有 RE 匹配的地方都替换成 replacement。如果没有找到任何匹配,那么返回原字符串。可选参数 count 指定最多替换的次数,必须是一个非负值。默认值是 0,意思是替换所有找到的匹配。下边是使用 sub() 方法的例子,它会将所有的颜色替换成 color:

subn:subn() 方法跟 sub() 方法干同样的事情,但区别是返回值为一个包含有两个元素的元组:一个是替换后的字符串,一个是替换的数目。

匹配方法:

匹配的方法和属性:

group(N) 返回第N组括号匹配的字符,groups() 返回所有括号匹配的字符,以tuple格式
match匹配的m:

findall() 需要在返回前先创建一个列表,而 finditer() 则是将匹配对象作为一个迭代器返回
利用compile来先编译的方法是模式级别的方法(适用于多次使用该正则表达式),可以针对同一种模式做多次匹配,如下图:另一种是模式对象方法
1 | import re import re |
匹配模式
贪婪模式和非贪婪模式:
贪婪模式是让正则表达式尽可能的匹配符合的内容
在匹配的字符后面加一个问号,启动非贪婪模式

编译标志
编译标志让你可以修改正则表达式的工作方式。在 re模块下,编译标志均有两个名字:完整名和简写
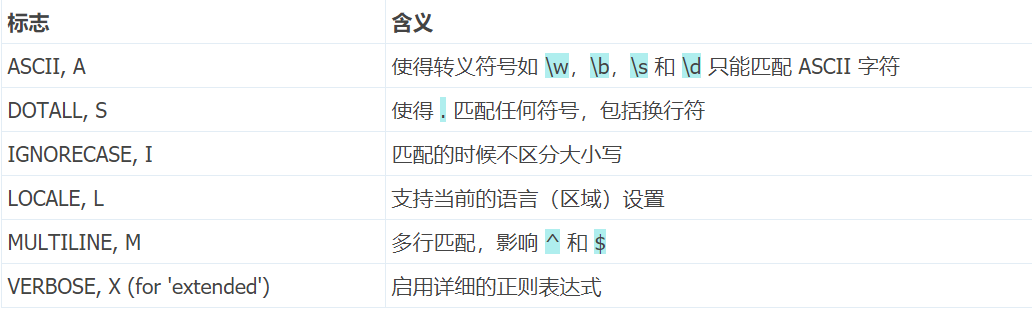
正则表达式特殊符号及用法:







